【导读】目标检测Yolo算法是非常经典且应用广泛的算法,而在Yolo中,又分成了输入端、网络推理、输出层,每个部分都可以延伸出很多的优化方式,本文主要从Yolov1~v7各个版本的Tricks进行了讲解,希望对大家有帮助。
近年来YOLO系列层出不穷,更新不断,已经到v7版本。本人认为不能简单用版本高低来评判一个系列的效果好坏,YOLOv1-v7不同版本各有特色,在不同场景,不同上下游环境,不同资源支持的情况下,如何从容选择使用哪个版本,甚至使用哪个特定部分,都需要我们对YOLOv1-v7有一个全面的认识。
故将YOLO系列每个版本都表示成下图中的五个部分,逐一进行解析,并将每个部分带入业务向,竞赛向,研究向进行延伸思考,探索更多可能性。
【Make YOLO Great Again】YOLOv1-v7全系列大解析(Neck篇),【Make YOLO Great Again】YOLOv1-v7全系列大解析(Head篇),【Make YOLO Great Again】YOLOv1-v7全系列大解析(输入侧篇)以及【Make YOLO Great Again】YOLOv1-v7全系列大解析(Backbone篇)已经发布,大家可按需取用~
而本文将聚焦于YOLO系列Tricks知识的分享,希望能让江湖中的英雄豪杰获益。
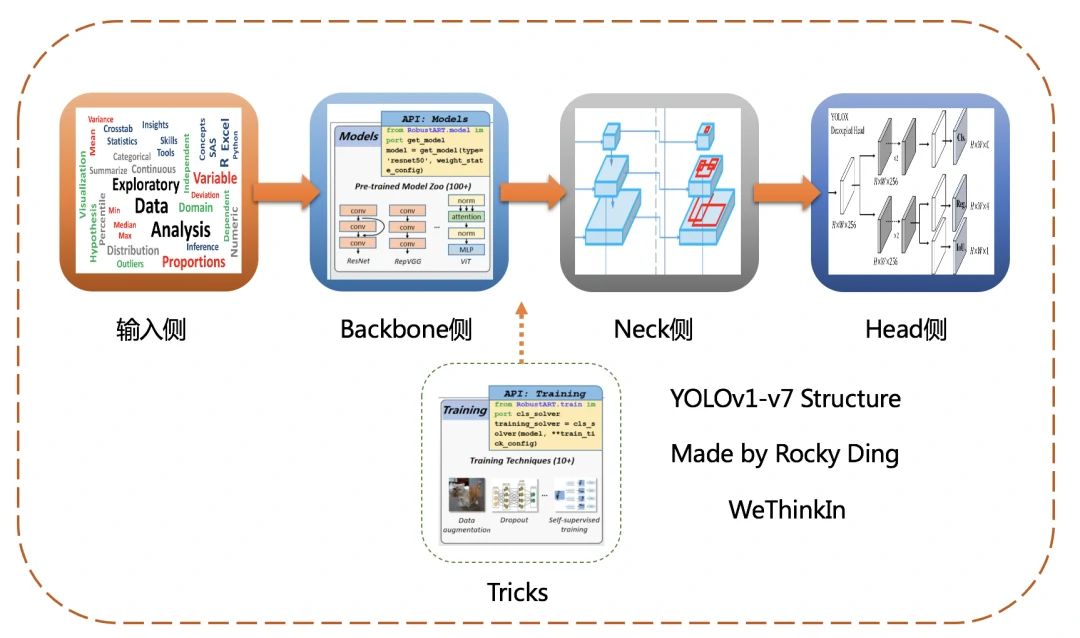
YOLOv1-v7论文&&项目名称
YOLOv1论文名:You Only Look Once: Unified, Real-Time Object Detection
YOLOv2论文名:YOLO9000: Better, Faster, Stronger
YOLOv3论文名:YOLOv3: An Incremental Improvement
YOLOv4论文名:YOLOv4: Optimal Speed and Accuracy of Object Detection
YOLOv5论文名:无
YOLOx论文名:YOLOX: Exceeding YOLO Series in 2021
YOLOv6论文名:YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
YOLOv7论文名:YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
YOLOv1开源代码:YOLOv1-Darkent
YOLOv2开源代码:YOLOv2-Darkent
YOLOv3开源代码:YOLOv3-PyTorch
YOLOv4开源代码:YOLOv4-Darkent
YOLOv5开源代码:YOLOv5-PyTorch
YOLOx开源代码:YOLOx-PyTorch
YOLOv6开源代码:YOLOv6-PyTorch
YOLOv7开源代码:Official YOLOv7-PyTorch
YOLO系列中Tricks的特点
YOLO系列中使用的Tricks,从横向角度来看,基本算是当时的最优Trcks;从纵向角度来看,其大部分都具备了可迁移性,强适应性,能够跟随着我们一起进入2020年代,并且依旧发挥余热。
YOLO系列中使用的Tricks和Backbone以及输入侧一样,是通用性非常强的一个部分,具备很强的向目标检测其他模型,图像分类,图像分割,目标跟踪等方向迁移应用的价值。
从业务向,竞赛向,研究向等角度观察,Tricks部分也能在这些方面比较好的融入,从容。
YOLOv1-v3 Tricks解析
作为YOLO系列的开山之作,YOLOv1中并未用太多的Tricks,但是设计出YOLO的架构,已经足够伟大。

YOLOv1整体结构
等到YOLOv2发布时,引入了当时来说比较有创造性的Tricks,即设计了分类与检测的联合训练方法,使得YOLO能够实时检测多达9000种目标,在这种方法下输出的模型称为YOLO9000。
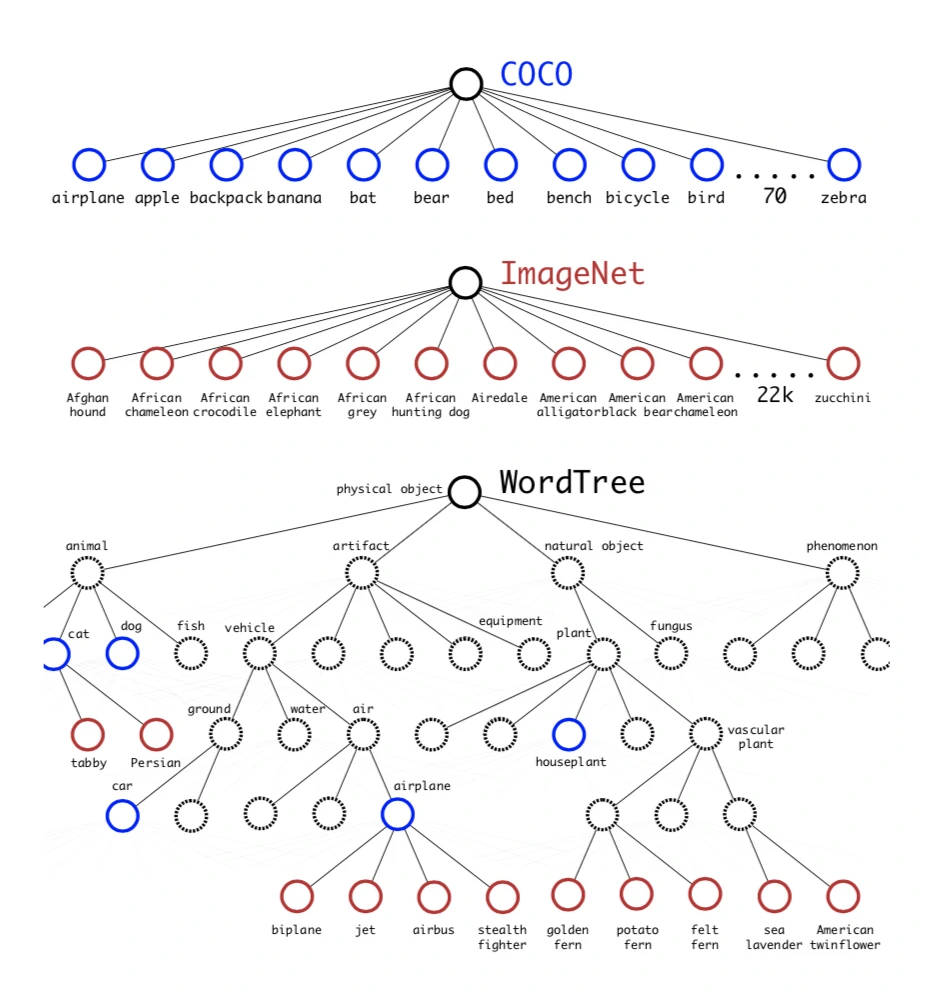
YOLO9000联合训练逻辑
YOLO9000主要在COCO和ImageNet数据集上进行训练,首先在检测数据集上训练一定的epoch来让模型学习定位和检测目标的能力;再使用分类数据集进行训练,从而扩展模型对目标的识别能力。
在训练的过程中,混合目标检测和分类的数据集。当输入是检测数据集时,对整个Loss函数计算Loss;当输入是分类数据集时,Loss函数只计算分类Loss,其余部分Loss设为零。
YOLO9000使用的联合训练不同于将Backbone在ImageNet上进行预训练,联合训练可以扩充检测识别的目标类别。例如,当模型检测出车的位置后,更进一步将其细分类别轿车、卡车、客车、自行车、三轮车等。
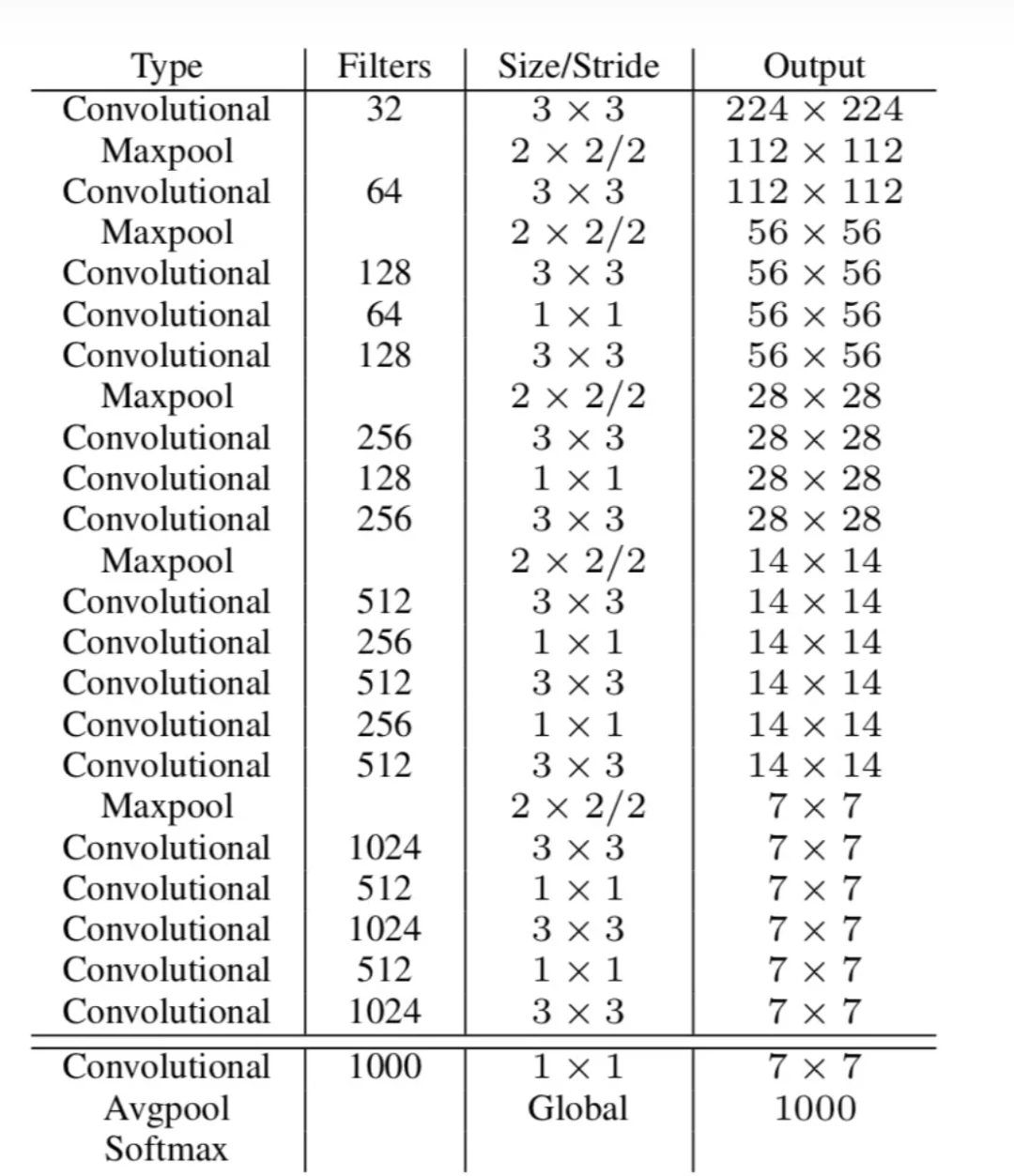
Darknet-19网络结构
等到YOLOv3发布时,YOLO系列的整体架构算是基本确定,Adam优化器也开始逐渐流行起来。
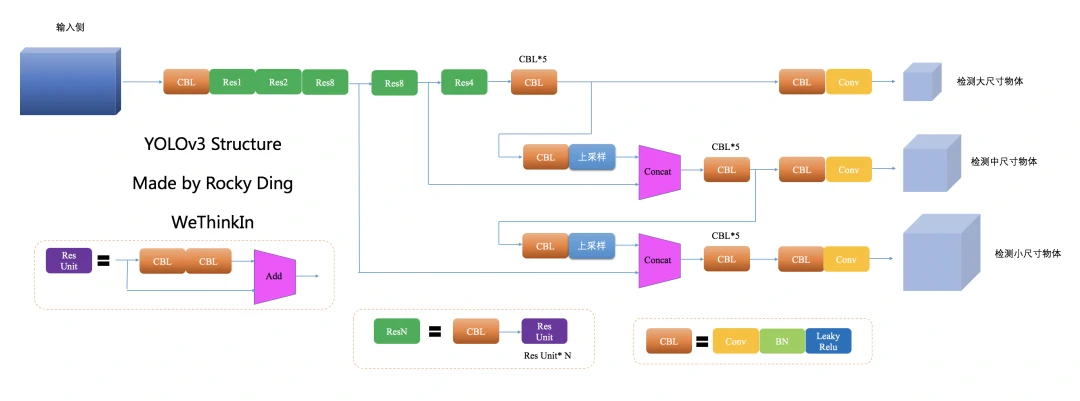
YOLOv3网络结构图
Adam优化器结合了AdaGrad和RMSProp两种优化算法的优点。对梯度的一阶矩估计(First Moment Estimation,即梯度的均值)和二阶矩估计(Second Moment Estimation,即梯度的未中心化的方差)进行综合考虑,计算出更新步长。
Adam的优势:
- 实现简单,计算高效,对内存需求少。
- 参数的更新不受梯度的伸缩变换影响。
- 超参数具有很好的解释性,且通常无需调整或仅需很少的微调。
- 更新的步长能够被限制在大致的范围内(初始学习率)。
- 能自然地实现步长退火过程(自动调整学习率)。
- 很适合应用于大规模的数据及参数的场景。
- 适用于不稳定目标函数。
- 适用于梯度稀疏或梯度存在很大噪声的问题。
Adam的实现原理:

【延伸思考】
- YOLOv1-v3中使用的Tricks无论是在业务向,竞赛向还是研究向,都可以作为入场Baseline。
YOLOv4 Tricks解析
YOLOv4在YOLOv3的基础上,设计使用了SAT,CmBN和Label Smoothing等Tricks。
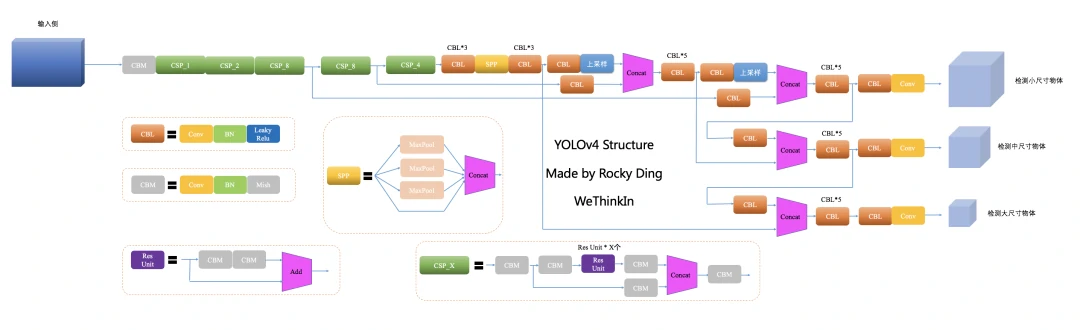
YOLOv4网络结构图
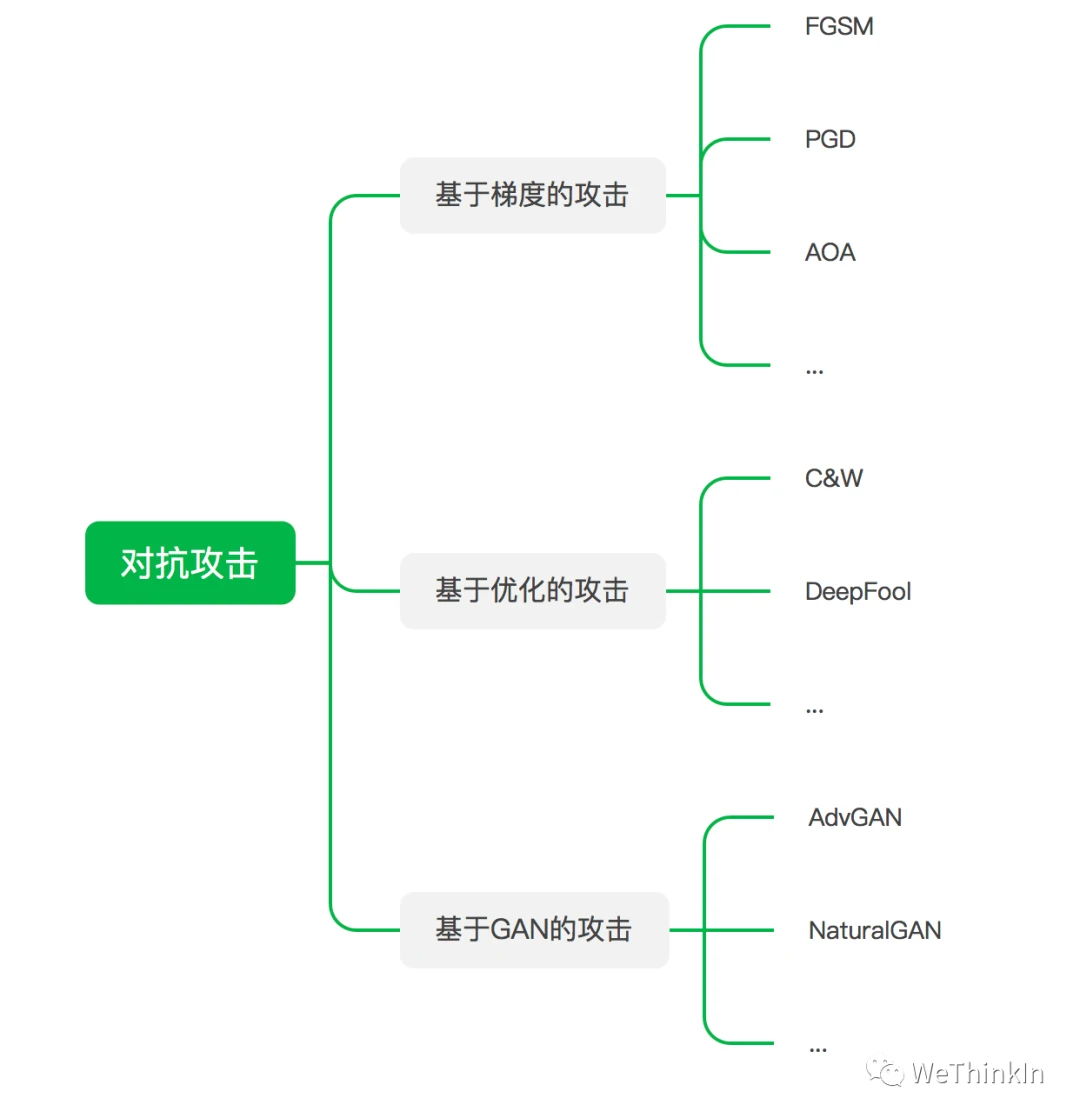
YOLOv4中的SAT(self adversarial training)使用基于FGSM原理的梯度攻击技术,生成对抗样本进行对抗训练。

首先,什么是对抗样本呢?对抗样本是在原图像中增加扰动噪声生成,如上图所示。对抗样本容易使得模型输出错误判断,这给模型的鲁棒性造成了重大挑战。
打不过,就加入它。秉持着这个原则,我们在训练时将对抗样本加入训练集一起训练,即为对抗训练。进行对抗训练能扩充训练集的可能性,使得数据集逼近我们想要的数据分布,训练后的模型鲁棒性和泛化性能也大大增强。
生成对抗样本的方法主要分为三种,具体逻辑如下图所示。
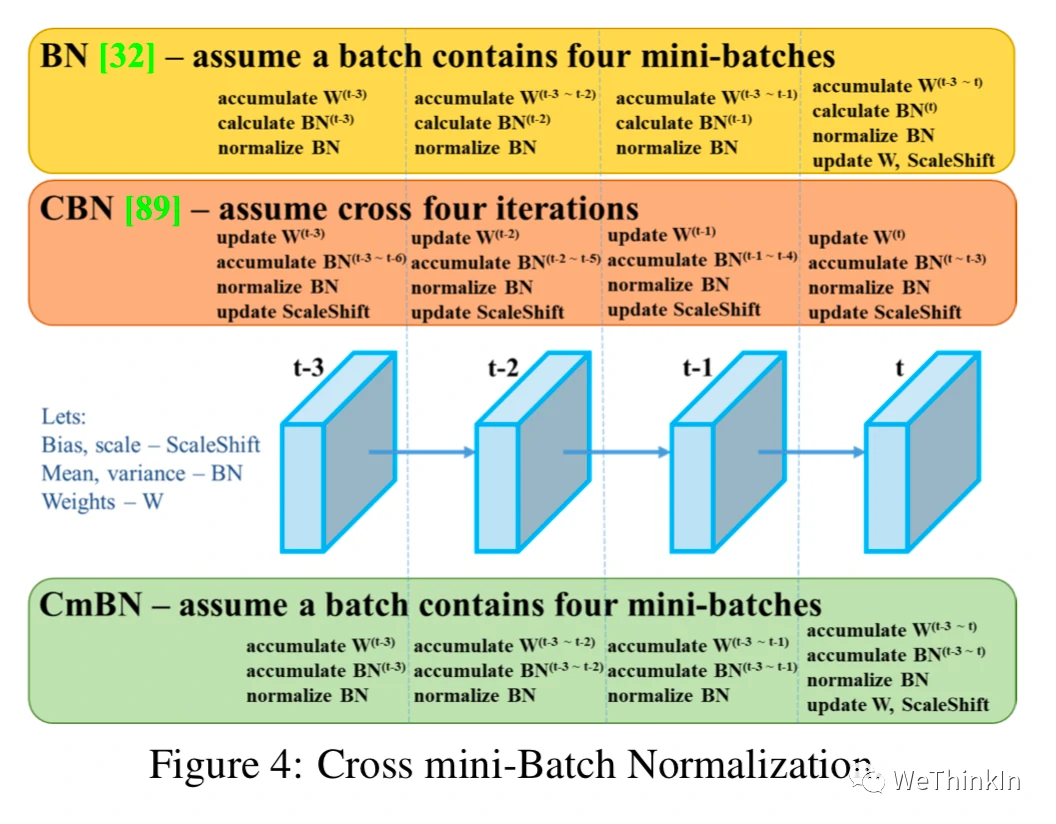
CmBN(Cross mini-Batch Normalization)是CBN的修改版。
CBN主要用来解决在Batch-Size较小时,BN的效果不佳问题。CBN连续利用多个迭代的数据来变相扩大Batch-Size从而改进模型的效果。(每次迭代时计算包括本次迭代的前四个迭代后统一计算整体BN)
而CmBN是独立利用多个mini-batch内的数据进行BN操作。(每四个迭代后统一计算一次整体BN)
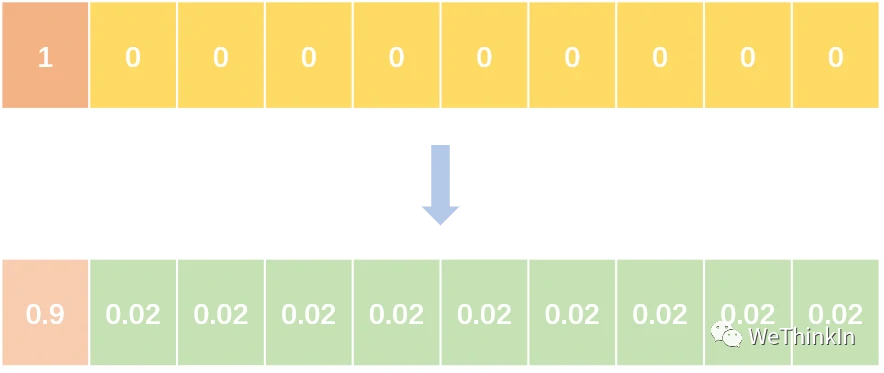
Label Smooth可以看作是一种防止过拟合的正则化方法。
其主要是在One-Hot标签中加入噪声,减少训练时GroundTruth在计算损失函数的权重,来达到防止过拟合的作用,增强模型的泛化能力。
通常参数设置如下图中的比例即可。
【延伸思考】
- YOLOv4中的Tricks具备在业务,竞赛以及研究中进行实验的价值。
YOLOv5 Tricks解析
YOLOv5中使用的Tricks基本上和YOLOv4一致,并在此基础上引入了更多的工程优化逻辑。
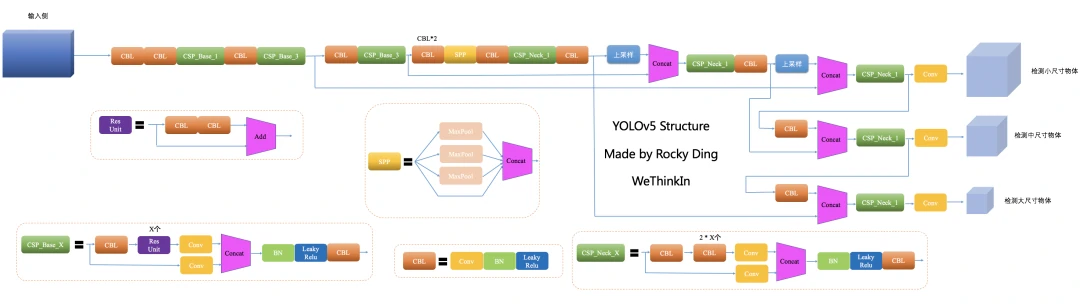
YOLOv5网络结构图
YOLOv5通过不同的训练参数配置,用来获得不同复杂度的模型。

YOLOv5模型家族
除此之外,YOLOv5还尝试了混合精度训练和模型EMA(Exponential Moving Average)策略。
混合精度训练能在尽可能减少精度损失的情况下利用FP16加速训练,并使用FP16存储模型权重,在减少占用内存的同时起到了加速训练的效果。
模型EMA(Exponential Moving Average)策略将模型近期不同epoch的参数做平均,提高模型整体检测性能以及鲁棒性。
【延伸思考】
- YOLOv5 Backbone的易用性使得其不管在业务向,竞赛向还是研究向都非常友好。
YOLOx Tricks解析
YOLOx使用了YOLOv5中提到的模型EMA(Exponential Moving Average)策略,并且使用余弦退火学习率优化训练过程。
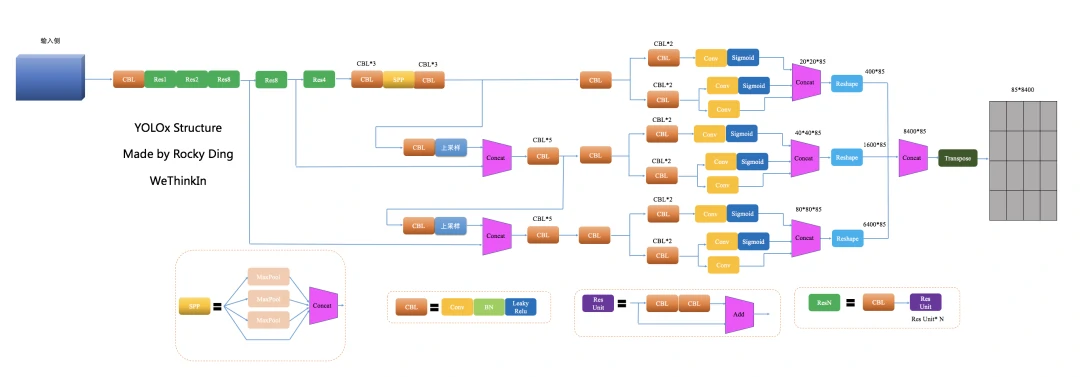
YOLOx网络结构图
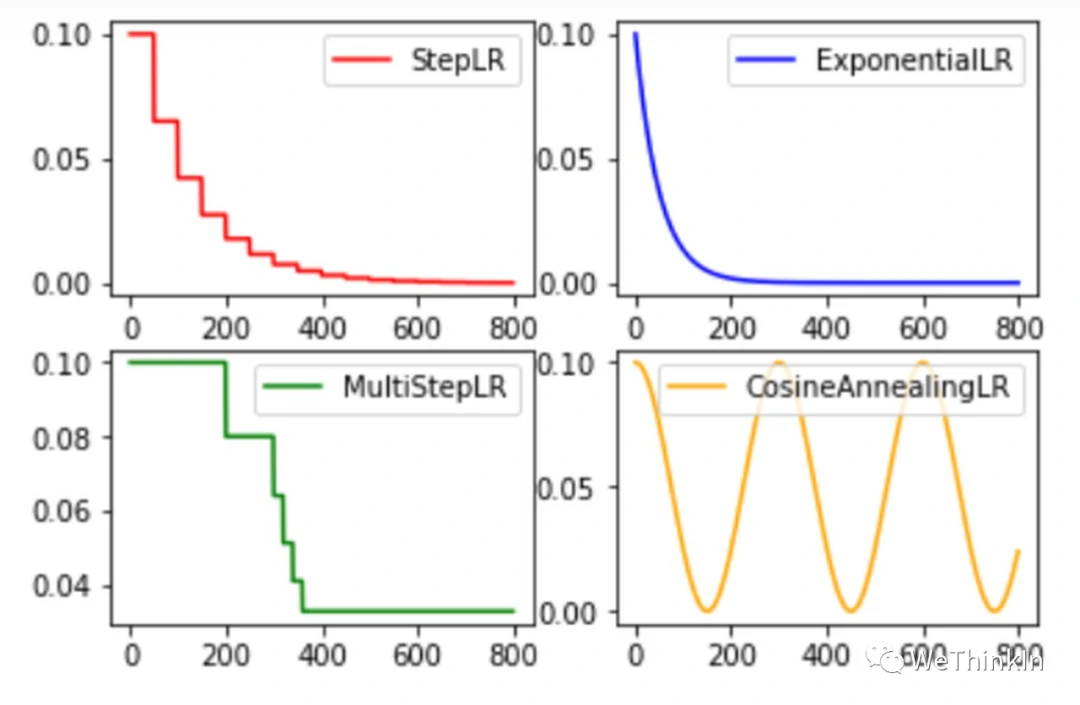
余弦退火学习率衰策略(CosineAnnealingLR)使得学习率呈周期性变化,但我们通常取它的一个余弦周期来完成整个训练过程。
另外,固定步长衰减(StepLR),多步长衰减(MultiStepLR),指数衰减(ExponentialLR)等都是经典实用的学习率衰减策略。
固定步长衰减在每隔一定的步长或者epoch对学习率进行一定衰减,而多步长衰减策略比起固定步长衰减则更加灵活,它可以在不同阶段使用不同强度和频率的衰减策略。指数衰减策略是使用指数逻辑对学习率进行衰减。
YOLOv6-v7 Tricks解析
YOLOv6进行了很多蒸馏方向上的尝试。
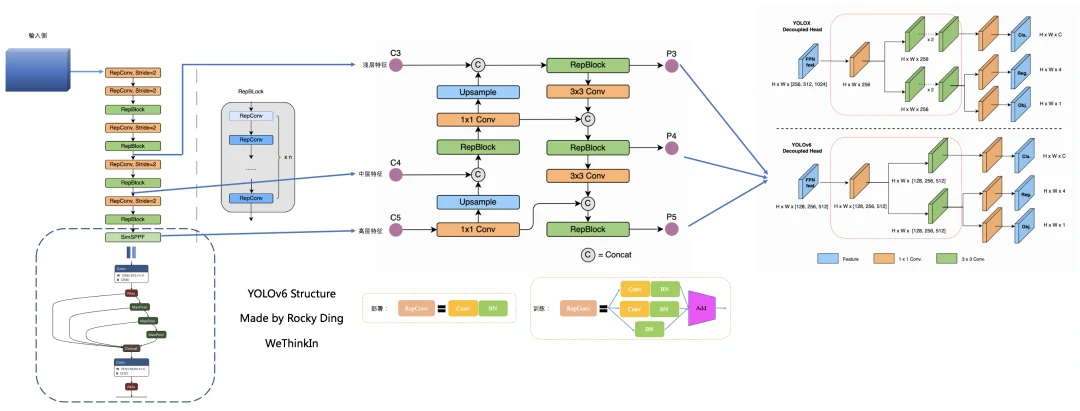
YOLOv6网络结构图
比如Self-distillation,Reparameterizing Optimizer,使用 Channel-wise Distillation进行量化感知训练等方法,进一步加强模型的整体性能。
YOLOv7也使用了YOLOv5中提到的模型EMA(Exponential Moving Average)策略,并引入了YOLOR中使用的隐性知识。
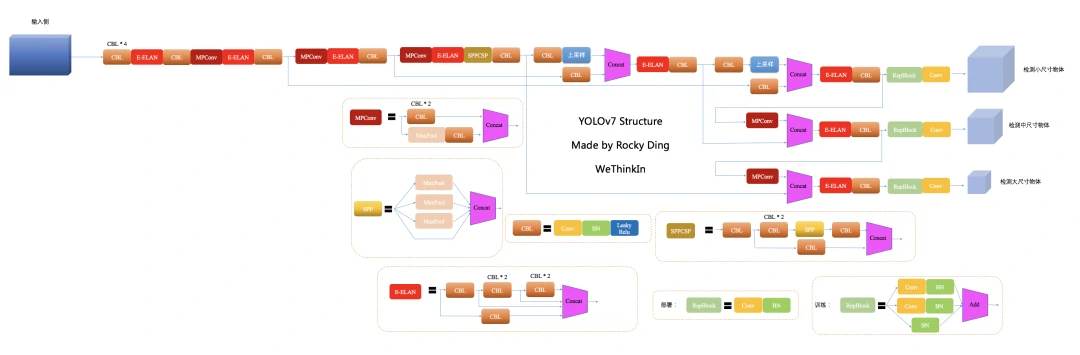
YOLOv7网络结构图
YOLOR中的隐式知识可以在推理阶段将计算值简化为向量。这个向量可以与前一层或后一层卷积层的偏差和权重相结合。
由于篇幅原因,在这里就不展开讲了,后续将专门对蒸馏技术撰写一篇总结文章,大家敬请期待!
【延伸思考】
- 蒸馏技术在业务,竞赛以及研究中的应用落地,以及蒸馏技术自身的发展,都是值得我们关注的地方。